Deep Learning 기초2 (Neural Net 기초)
김성훈 교수님의 “모두를 위한 머신러닝/딥러닝 강의(시즌1)”를 듣고 내용을 정리해 둔다. 참고한 문서들은 가장 아래 적어 둔다.
Introduction
Perceptron
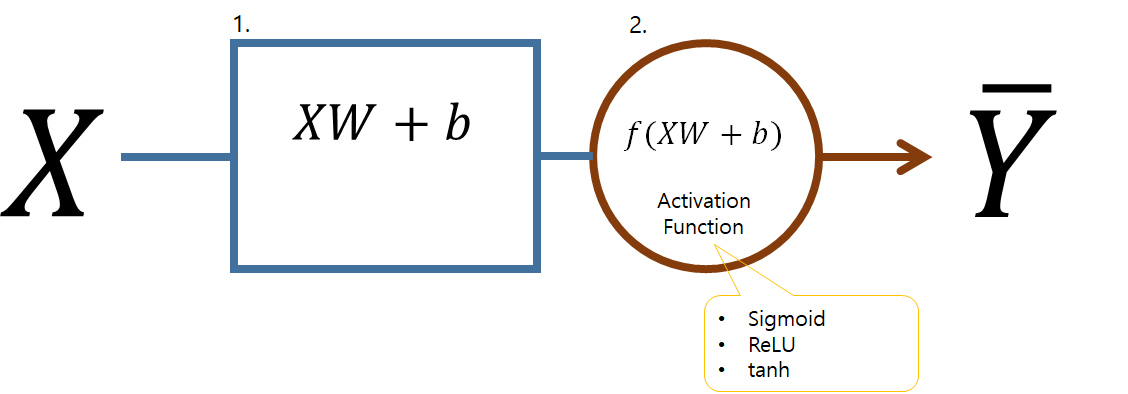
# tensorflow example
# W1 : weight1, b1 : bias1
# 1. sum
sum1 = tf.matmul( X, W1 ) + b1
# 2. activation
layer1 = tf.sigmoid( sum1 )
Major Issues
Geoffrey Hinton’s summary of findings up to today
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow.
- We initialized the weights in a stupid way.
- We used the wrong type of non-linearity.
Select Activation Function
We used the wrong type of non-linearity. _ Geoffrey Hinton
- Sigmoid를 사용할 경우 layer가 많아지면 최적화 단계에서 Backpropagation(chain rule)이 잘 전달되지 않는 문제가 발생한다. ( 결과값이 1보다 작은 값을 가지므로 곱해질 수록 값이 점점 작아진다. …. )
- Sigmoid 대신 ReLU 등을 사용하여 극복할 수 있다.
# ReLU
max(0, x)
# ReLU in tensorflow
tf.nn.relu()
Weight Initialization
We initialized the weights in a stupid way. _ Geoffrey Hinton
- 초기값을 잘못 잡으면 학습이 잘 되지 않는다.
- 그렇다면 가장 효과적인 초기값 설정 방법은 무엇인가?
Xavier/He initialization
# Xavier initialization (Glorot et al. 2010)
W = np.random.randn( fan_in, fan_out ) / np.sqrt( fan_in )
# He et al. 2015
W = np.random.randn( fan_in, fan_out ) / np.sqrt( fan_in / 2 )
Overfitting
- Neural Net에서 overfitting의 문제가 자주 발생할 수 있다.
- 이를 피하기 위한 Regularization의 방법으로
Dropout과Ensemble을 사용할 수 있다.
▶ Dropout
randomly set some neurons to zero in the forward pass _ Srivastava et al. 2014
tf.nn.dropout( layer, dropout_rate )
▶ Ensemble
- 여러개의 학습결과를 합쳐서 결론을 도출하는 방법
CNN: Convolutional Neural Networks
RNN : Recurrent Neural Networks
Acknowledgement
모두를 위한 머신러닝/딥러닝 강의



